
今天,我将展示如何使用令人印象深刻的Hailo AI Hat在树莓派5上训练、编译和部署自定义模型。注意:文章内的链接可能需要科学上网。
Hailo AI Hat
根据你的设置,在树莓派5的CPU上运行YOLO每秒可以提供1.5到8帧(FPS)。尽管对于这样一个小设备来说,这一性能已经相当出色,但对于许多实时应用来说,这还不够快。如果你需要更高的性能,就需要外部硬件。目前,Hailo为树莓派5设计的AI Hat是一个极佳的选择。
Hailo是一家专注于开发人工智能硬件的芯片制造商。在这个故事中,我感兴趣的是他们专门为树莓派5打造的AI Hat+设备:

我的树莓派 5带AI Hat+ Hailo8,还有Camera Noir v2
这款AI Hat有两个版本,一个搭载Hailo-8芯片,据说可以提供26 TOPS(每秒万亿次运算),另一个搭载Hailo-8L芯片,提供13 TOPS。
在这个故事中,我将使用搭载Hailo8架构的AI Hat版本。
为什么选择Docker?
准备好下载并安装千兆字节的第三方库吧。我们将使用Docker容器作为隔离环境,来配置和安装所需的一切,而无需修改主机。
也就是说,我们需要设置两个不同的Docker容器:
YOLOv5容器:这个容器有两个任务。首先,我们将使用自定义数据集训练模型。其次,我们将模型转换为ONNX格式。
Hailo容器:这个容器用于将ONNX文件转换为Hailo的HEF格式。
尝试使用同一个Docker容器来完成这两项任务,会因为库(如numpy)的冲突而带来不必要的麻烦。相信我,使用Docker来做它设计的事情,可以节省你的时间!
第一个Dockerfile由Hailo提供。第二个Dockerfile将在这个故事的后面部分提供。
本例中使用的数据集
我将使用Tech Zizou标记口罩数据集。你可以在这里找到它。
nature中发现的Tech Zizou标签口罩数据
从Kaggle下载文件,并按照以下方式解压:
mkdirsourceunzip -qq archive.zip -dsource/
source/obj中的文件结构不符合YOLO的预期。希望下面的代码能解决这个问题:
importos, shutil, random# preparing the folder structurefull_data_path ='source/obj/'extension_allowed ='.jpg'split_percentage =90images_path ='datasets/images/'ifos.path.exists(images_path): shutil.rmtree(images_path)os.mkdir(images_path)labels_path ='datasets/labels/'ifos.path.exists(labels_path): shutil.rmtree(labels_path)os.mkdir(labels_path)training_images_path = images_path +'train/'validation_images_path = images_path +'val/'training_labels_path = labels_path +'train/'validation_labels_path = labels_path +'val/'os.mkdir(training_images_path)os.mkdir(validation_images_path)os.mkdir(training_labels_path)os.mkdir(validation_labels_path)files = []ext_len =len(extension_allowed)forr, d, f in os.walk(full_data_path): forfile in f: iffile.endswith(extension_allowed): strip = file[0:len(file) - ext_len] files.append(strip)random.shuffle(files)size =len(files) split =int(split_percentage * size /100)print("copying training data")fori inrange(split): strip = files[i] image_file = strip + extension_allowed src_image = full_data_path + image_file shutil.copy(src_image, training_images_path) annotation_file = strip +'.txt' src_label = full_data_path + annotation_file shutil.copy(src_label, training_labels_path)print("copying validation data")fori inrange(split, size): strip = files[i] image_file = strip + extension_allowed src_image = full_data_path + image_file shutil.copy(src_image, validation_images_path) annotation_file = strip +'.txt' src_label = full_data_path + annotation_file shutil.copy(src_label, validation_labels_path)print("finished")
这段代码假设数据在source/obj/文件夹中,并将输出数据放入datasets文件夹中。将文件命名为tidy_data.py,并按照以下方式运行:
mkdirdatasetspython tidy_data.py
准备数据
我们最终得到以下结构:
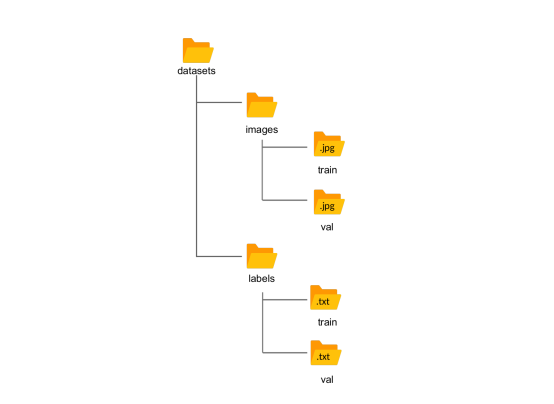
Yolo预期的文件夹结构
这里有一些需要注意的事项:
这个数据集只有两个类别:戴口罩和不戴口罩。
只有1359张训练图像和151张验证图像。
训练数据量很小。仅使用这些数据从头开始训练模型将产生非常差的模型,这种情况称为过拟合。
我们在这里不深入探讨建模细节。无论如何,为了简化事情,我们将使用一种称为迁移学习的技术,即在训练开始前,将预训练的权重输入到模型中。特别是,我们将使用Ultralytics提供的使用COCO数据库训练的权重。
YOLOv5
Ultralytics的最新YOLO版本是11。
它比YOLOv5更快、更准确。但这并不意味着YOLOv5已经过时。实际上,Ultralytics明确表示,在某些特定场景下,YOLOv5是更优的选择。
在这个故事中,我有充分的理由避免使用YOLO 11:Hailo堆栈目前还不支持YOLO 11。
如果你真的不想使用YOLOv5,你可以轻松地将这个故事改编为使用YOLO 8。
Linux,朋友,Linux!
这个故事使用Linux,具体来说是Ubuntu LTS。
对于人工智能开发,我推荐使用Ubuntu 20.04或22.04。LTS一路相伴!
任务简报
整个过程由三个简单的步骤组成:
步骤1:训练自定义模型:在这一步中,我们使用自定义数据加上预训练的YOLOv5权重来训练模型,以执行我们的检测任务(在我们的例子中,是检测戴或不戴口罩的脸)。这一步的输出是一个pytorchbest.pt文件。这个文件只包含我们模型的参数值。
步骤2:将best.pt转换为ONNX格式:ONNX是一种用于机器学习模型的开放格式。这一步的输出是一个best.onnx文件。
步骤3:将best.onnx转换为HEF格式:Hailo可执行格式是一种专门为在Hailo芯片上运行而高度优化的模型。在这一步中,我们将ONNX文件转换为HEF文件。
一旦我们有了.hef格式的模型,我们只需将其部署到树莓派上并进行测试。
步骤1:训练你的自定义数据
为Hailo架构训练模型并没有什么新奇之处。你可以像往常一样训练你的模型。
如果你已经有了模型,就跳过这一步。否则,请继续阅读。
首先,如果系统中还没有安装Docker,请安装它。
同时,安装NVIDIA Container Toolkit。
Hailo在GitHub上共享了一个包含所需资源的仓库。克隆它:
gitclonehttps://github.com/hailo-ai/hailo_model_zoo
克隆 the hailo_model_zoo 仓库
我们在hailo_model_zoo/training/yolov5文件夹中寻找YOLOv5训练的Dockerfile。移动到这个文件夹,并使用以下命令构建镜像:
cdhailo_model_zoo/training/yolov5docker build -t yolov5:v0 .
构建镜像
现在,运行容器:
docker run-it--name custom_training--gpus all--ipc=host-v/home/doleron/hailo/shared:/home/hailo/shared yolov5:v0
简而言之,-it标志要求Docker以交互模式运行容器,这对于后续执行命令是必要的。
参数-v /home/doleron/hailo/shared:/home/hailo/shared将我机器上的/home/doleron/hailo/shared文件夹映射到容器机器上的/home/hailo/shared文件夹。
--gpus all指示Docker使用主机上可用的任何GPU。
现在,我们在容器内部。我们可以检查/home/hailo/shared的内容,以确保我们的数据集文件在那里:
ls/home/hailo/shared/ -als
使用交互模式运行容器
这个容器没有nano编辑器。除非你是Vim用户,否则我建议按照以下方式安装nano:
sudoapt updatesudo apt install nano -y
安装完nano后,我们可以继续并设置我们的训练。将datasets文件夹复制到workspace文件夹中:
cp-r /home/hailo/shared/datasets ..
现在,编写data/dataset.yaml文件:
nano data/dataset.yaml
这是data/dataset.yaml的内容:
train: ../datasets/images/trainval: ../datasets/images/valnc: 2names: 0:'using mask' 1:'without mask'
按control-x,y,然后Enter保存文件并退出nano。
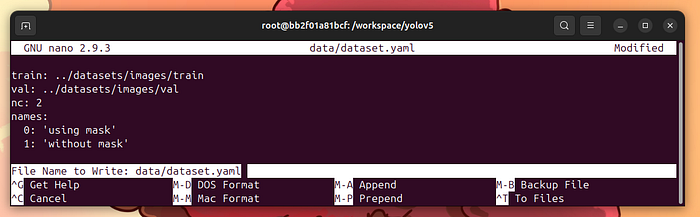
创建data/dataset.yaml文件
是时候训练我们的模型了!确保你在/workspace/yolov5文件夹中,并输入:
python train.py--img640--batch16--epochs100--datadataset.yaml--weightsyolov5s.pt
如果你遇到类似RuntimeError: CUDA out of memory的错误,尝试将--batch 16减少到--batch 8或更少。
我希望你熟悉基本的机器学习术语:batches、epoch等。你可以按照这份指南调整这些超参数。
https://docs.ultralytics.com/zh/guides/hyperparameter-tuning/
如果一切顺利,你的GPU将开始全力运转:
我的RTX 4070在燃烧!
保持温度在81°C以下,你就没事。
在我的情况下,这次训练大约用了40分钟。
作为参考,使用另一台配备GTX 1080的机器大约需要2小时。
最后,你会得到类似这样的结果:
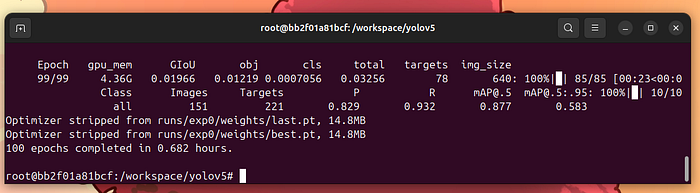
训练结束
这意味着训练已经完成。我们可以在runs/exp0文件夹中检查结果。将这个文件夹复制到共享区域:
mkdir/home/hailo/shared/runscp-r runs/exp0 /home/hailo/shared/runs/
你最终会得到一个这样的文件夹:
训练结果文件夹
我们可以检查训练结果:
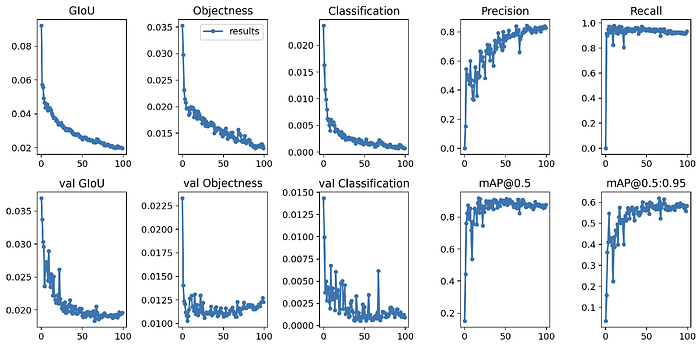
训练结果
比较第一行图表(训练性能)和第二行图表(验证性能),我们发现模型没有过拟合。
值得一提的是,使用不同的验证实例集是评估模型质量的首要要求。
可以使用常规的机器学习工程技术来改进模型,以达到更高的性能。然而,这并不是我们现在的重点。
记住:我们的重点是学习如何在树莓派/Hailo AI Hat上使用这样的模型。
让我们进入下一步!
步骤2:将best.pt文件转换为ONNX
回到容器中,最好的权重文件是runs/exp0/weights/best.pt。我们可以使用以下命令将其转换为ONNX:
python3 models/export.py --weights runs/exp0/weights/best.pt --img 640
注意,best.onnx已经生成:
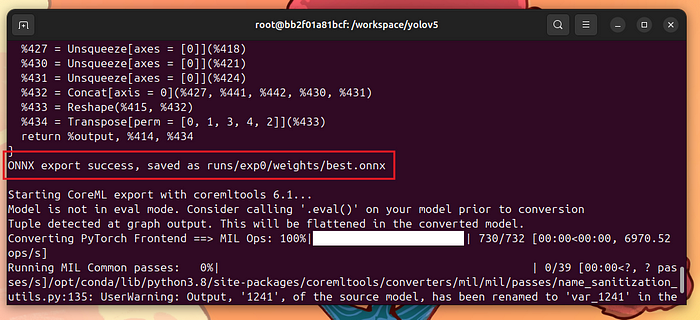
将best.pt转换成best.onnx
将best.onnx复制到主机机器上:
cpruns/exp0/weights/best.onnx /home/hailo/shared/
我们已经完成了这个容器的任务。如果你想退出,就退出吧。
步骤3:将ONNX转换为HEF
本教程中最简单的部分是使用YOLOv5训练自定义模型并将结果文件转换为ONNX。现在,是时候将ONNX文件编译成专有的Hailo可执行格式(HEF)了。
在任何地方启动一个新的终端,并编写这个Dockerfile:
# using a CUDA supported Ubuntu 22.04 image as baseFROM nvidia/cuda:12.4.1-cudnn-runtime-ubuntu22.04 AS base_cudaENV DEBIAN_FRONTEND=noninteractiveENV PYTHONDONTWRITEBYTECODE=1ENV PYTHONUNBUFFERED=1RUN apt-get update && \ apt-get install -y \ # see: the Hailo DFC user guide python3.10 \ python3.10-dev \ python3.10-venv \ python3.10-distutils \ python3-pip \ python3-tk \ graphviz \ libgraphviz-dev \ libgl1-mesa-glx \ # utilities python-is-python3 \ build-essential \ sudo \ curl \ git \ nano && \ # clean up rm-rf /var/lib/apt/lists/*# update pipRUN python3 -m pip install --upgrade pip setuptools wheelWORKDIR /workspaceARG user=hailoARG group=hailoARG uid=1000ARG gid=1000RUN groupadd --gid$gid$group&& \ adduser --uid$uid--gid$gid--shell /bin/bash --disabled-password --gecos""$user&& \ chmodu+w /etc/sudoers &&echo"$userALL=(ALL) NOPASSWD: ALL">> /etc/sudoers &&chmod-w /etc/sudoers && \ chown-R$user:$group/workspace
将其保存为Dockerfile,并使用以下命令构建镜像:
dockerbuild -t hailo_compiler:v0 .
一旦镜像构建完成,按照以下方式启动容器:
docker run-it--name compile_onnx_file--gpus all--ipc=host-v/home/doleron/hailo/shared:/home/hailo/shared hailo_compiler:v0
这个命令会给我们一个容器机器内的命令提示符:
运行新Docker容器
这看起来像是似曾相识。我们在上一节中刚刚执行了类似的步骤。那又怎样?
关键在于:我们正在挂载第二个隔离容器来安装Hailo的东西,而不用担心与其他库的冲突。特别是,我们需要安装三个包:
Hailort:Hailo运行时平台
Hailort Wheel:Hailort Python库
Hailo DFC:Hailo数据流编译器
FOSS社区习惯了开源生态系统。在这个上下文中,一切都可以从公开可用的仓库中安装。然而,Hailo在人工智能市场这个充满挑战和野性的商业世界中运作。因此,他们的软件还不是开源的。希望Hailo的软件至少是免费的。
要使用Hailo的东西,我们必须在Hailo Network上创建一个账户.
访问软件下载页面,并下载三个包:
hailort_4.21.0_amd64.deb
hailort-4.21.0-cp310-cp310-linux_x86_64.whl
hailo_dataflow_compiler-3.31.0-py3-none-linux_x86_64.whl
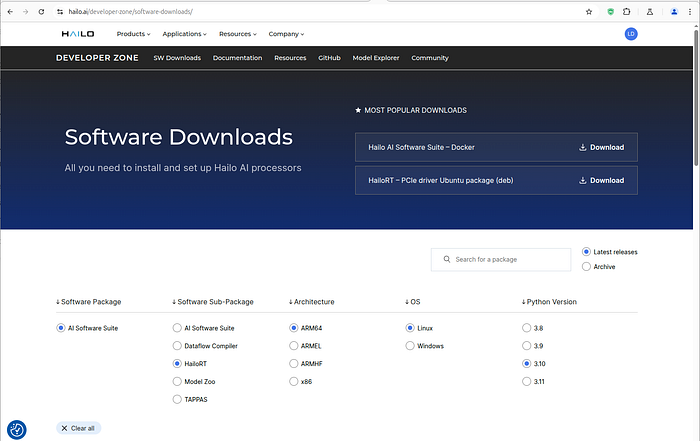
Hailo 网络下载页面
将它们保存在共享文件夹的某个地方,并将它们复制到容器中:
cp/home/hailo/shared/libs/* .
在安装软件之前,为Python创建一个虚拟环境并激活它:
python -m venv .venvsource.venv/bin/activate
然后,安装Hailo RT包:
dpkg-i ./hailort_4.21.0_amd64.deb
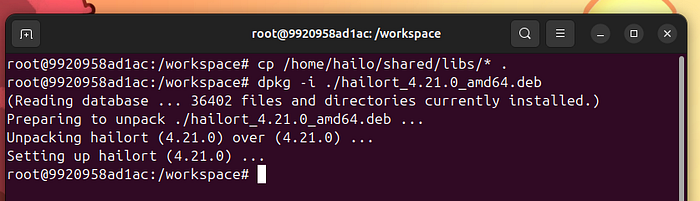
安装Hailo RT
接下来,安装Hailo RT Python API:
pipinstall ./hailort-4.21.0-cp310-cp310-linux_x86_64.whl
现在,安装Hailo DFC:
pipinstall ./hailo_dataflow_compiler-3.31.0-py3-none-linux_x86_64.whl
注意,包版本表示在这个故事编写时Hailo软件的当前阶段。它们必须与容器Python版本(3.10)匹配。
我们还没完成。我们必须克隆并安装hailo_model_zoo:
gitclonehttps://github.com/hailo-ai/hailo_model_zoo.gitcdhailo_model_zoopip install -e .
检查hailomz是否正确设置:
hailomz--version
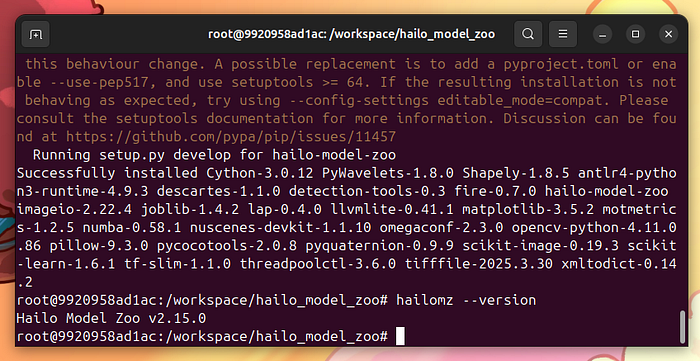
安装Hailo内容
坚持住!最困难的部分现在来了:将best.onnx文件编译成best.hef文件。
要使这工作,我们需要将hailo_model_zoo/cfg/postprocess_config/yolov5s_nms_config.json中的类别数更改为2:
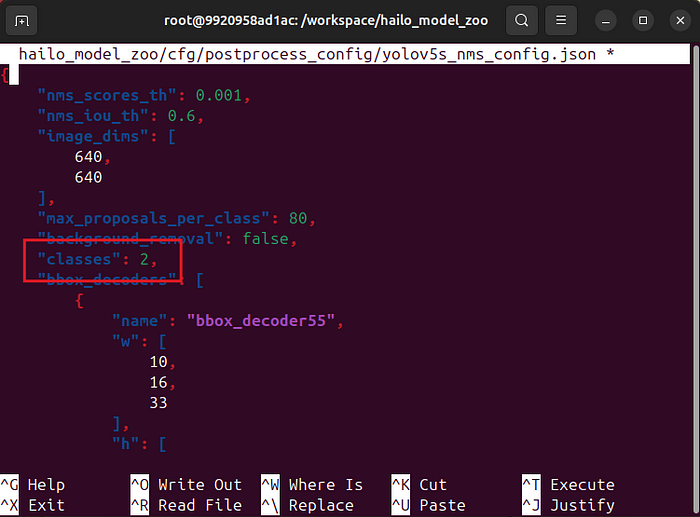
请注意,在hailo_model_zoo仓库中有一个hailo_model_zoo文件夹!
在开始编译器之前,设置USER环境变量:
exportUSER=hailo
现在,按照以下方式调用hailomz:
hailomz compile--ckpt/home/hailo/shared/best.onnx--calib-path/home/hailo/shared/datasets/images/train/--yaml hailo_model_zoo/cfg/networks/yolov5s.yaml
慢慢来。等待10分钟,让hailomz优化并编译你的模型:
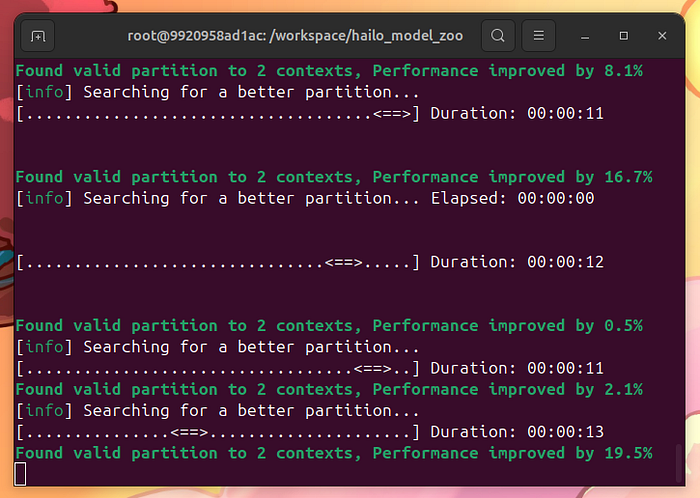
用hailomz编译模型
如果一切顺利,你会得到以下消息:
HEF 编译
注意,将ONNX转换为HEF包括一个新元素:校准图像。校准图像是Hailo编译器用于优化模型的特性空间的示例。我在这里没有找到任何文档,但一旦hailomz编译器警告我使用超过1024个实例,使用相同的训练集似乎就能工作。
将yolov5s.hef复制到共享区域:
cpyolov5s.hef /home/hailo/shared/
最困难的部分已经完成。我们可以退出容器实例。
在树莓派5上部署模型
将yolov5s.hef复制到树莓派上。
在树莓派上运行Hailo应用程序的细节超出了这个故事的范围。
在树莓派上,运行以下命令:
gitclonehttps://github.com/hailo-ai/hailo-rpi5-examples.gitcdhailo-rpi5-examplessourcesetup_env.shpython basic_pipelines/detection.py --labels-json custom.json --hef-path /home/pi/Documents/yolov5s.hef --input /home/pi/Documents/videoplayback.mp4 -f
其中custom.json是:
{ "detection_threshold":0.5, "max_boxes":200, "labels":[ "unlabeled", "with mask", "without mask" ]}
使用这个视频的结果是:
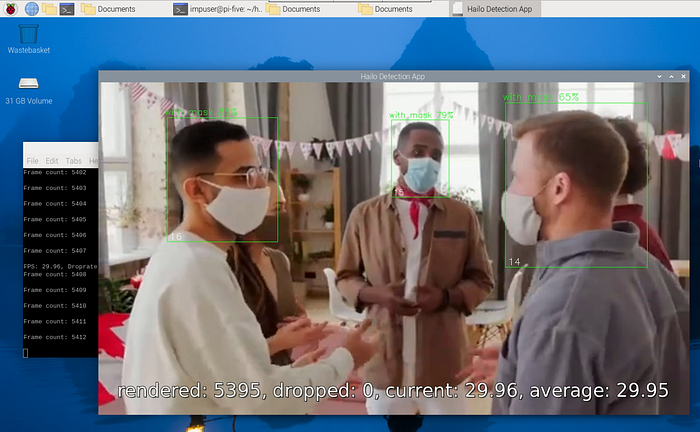
即使在高清分辨率下,对象检测也能达到30 fps。这是令人印象深刻的!您可以探索其他输入类型,例如:
python basic_pipelines/detection.py --labels-json custom.json --hef-path /home/pi/Documents/yolov5s.hef --input usb -f
或者
python basic_pipelines/detection.py --labels-json custom.json --hef-path /home/pi/Documents/yolov5s.hef --input rpi -f
查看Hailo RPI示例仓库以获取更多参数和用法示例。
https://github.com/hailo-ai/hailo-rpi5-examples
使用其他YOLO版本
值得注意的是,在撰写本文时,Hailo模型编译器仅与YOLO3、YOLO4、YOLOv5、YOLOv8和YOLOX进行了测试。
查看Hailo开发者专区,了解Hailo编译器何时将支持更早的YOLO版本。
结论
我们展示了使用Hailo AI Hat在树莓派5上训练自定义数据集、编译和部署模型的完整步骤序列。
我期待着弄清楚AI Hat能做什么。但这是另一个故事的话题了。
原文地址:
https://pub.towardsai.net/custom-dataset-with-hailo-ai-hat-yolo-raspberry-pi-5-and-docker-0d88ef5eb70f