
1月20日至27日,第40届 (AAAI 2026) 于新加坡召开,汇聚世界顶尖学者与先锋研究者,以智慧碰撞共绘人工智能的未来图景。在端到端自动驾驶领域,将扩散模型的“迭代细化”能力应用于轨迹规划,以应对驾驶行为中的多模态挑战,是热点研究方向之一。由 Nullmax 研发团队与浙江大学学子共同撰写,此次入选 AAAI 2026 的轨迹预测框架 DiffRefiner,正是对这一技术方向的深入探索,验证了扩散模型在轨迹规划中的可行性与优越性。本文将对该项成果进行系统解读。
论文标题:DiffRefiner: Coarse to Fine Trajectory Planning via Diffusion Refinement with Semantic Interaction for End to End Autonomous Driving
论文链接:https://arxiv.org/abs/2511.17150
DiffRefiner 是由 Nullmax 提出的最新端到端自动驾驶规划框架。不同于传统只做单阶段回归或单纯扩散生成的工作,DiffRefiner 通过由粗到精轨迹预测框架,实现了“生成式+判别式”的混合范式,把判别式的高效规划和生成式的多样性建模有机结合。在两个公开基准测试——真实道路数据集 NAVSIM v2 和闭环仿真基准 Bench2Drive中,DiffRefiner均取得了当前最优(SOTA)性能。
由粗到精框架,混合范式实现更类人决策
在整体架构上,DiffRefiner 包含“感知模块 + 提案解码器 + 扩散精炼器”三大组件。首先,我们利用基于 BEV 的感知网络同时完成目标检测与语义分割,构建结构化的场景表示;随后,一个轻量级 Transformer 提案解码器在预先聚类得到的轨迹锚点上做回归调整,生成一组符合场景先验的粗轨迹提案,作为后续扩散过程的强引导。这种“锚点先粗拟合、扩散再精修正”的混合范式,有效模拟了人类先确定大方向、再不断微调的决策过程。既保留了判别式方法的稳定和高效,又充分发挥了扩散模型在多模态轨迹建模上的优势。
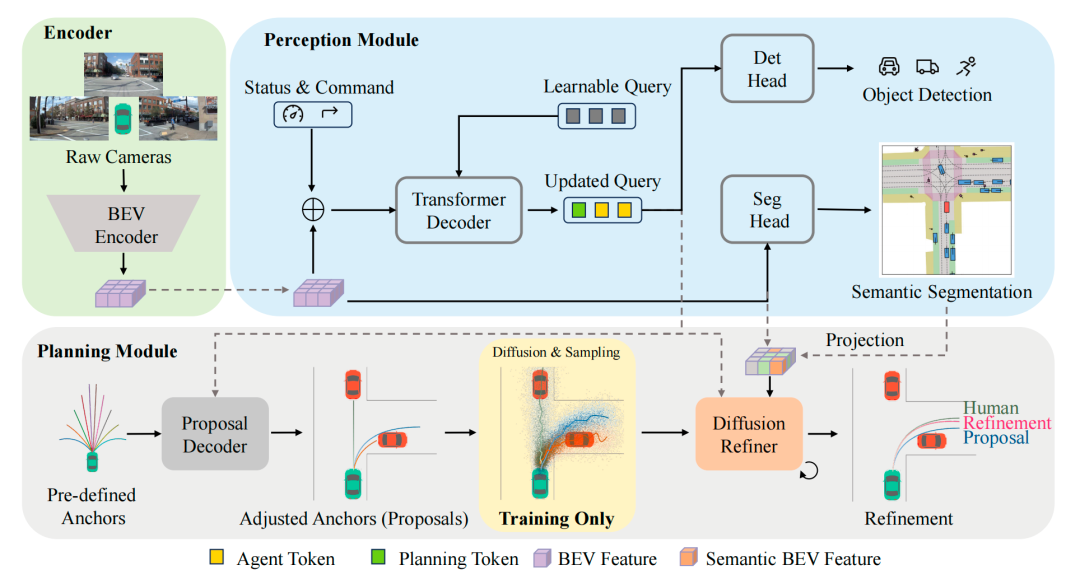
细粒度语义交互,让规划“看懂场景”
为了让规划真正“看懂场景”、贴合道路与交通参与者,DiffRefiner 设计了 Fine-Grained Semantic Interaction Module (FGSIM) 细粒度语义交互模块。该模块分两步工作:先通过跨注意力将轨迹特征与可行驶区域等 BEV 语义区域建立全局关联,再通过可变形注意力聚焦于车道线、路口等关键局部结构和周围动态目标,最后由门控融合网络自适应地平衡全局上下文与局部细节。结合约束式扩散解码器,DiffRefiner 能在极少的反推步数(甚至单步)内完成高质量精炼,实现真正可落地的实时端到端规划。
刷新纪录,双基准达成SOTA性能
实验数据显示,在真实道路数据集 NAVSIM v2 和闭环仿真基准 Bench2Drive 上,DiffRefiner 都刷新了当前最优成绩。在性能方面,DiffRefiner 在 NAVSIM v2 上取得 87.4 的 EPDMS,在 Bench2Drive 上获得 87.1 的 Driving Score 和 71.4 的 Success Rate,双双刷新公开基准的最好记录,并在合流、超车、礼让、紧急制动等多项能力指标上领先现有方法,展现了在复杂交互场景中的强鲁棒性与安全性。此外,消融实验也进一步验证了各组件的有效性。
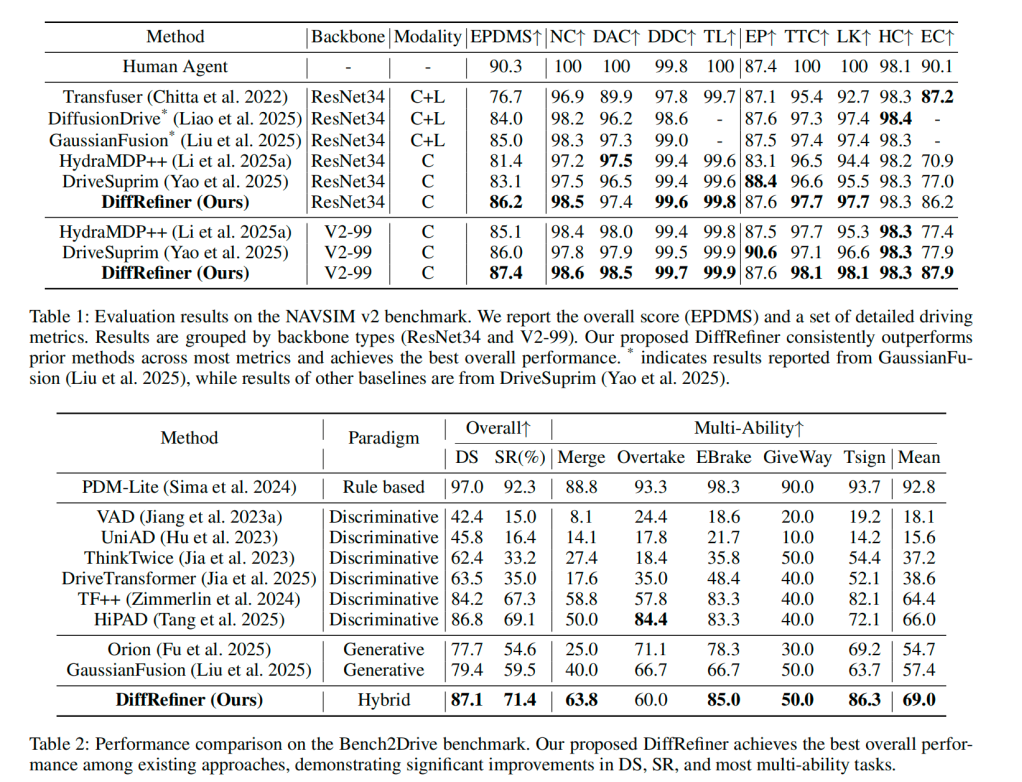
近年来,端到端自动驾驶研究进展显著,然而基于纯回归的方法在处理轨迹预测的多模态分布时存在固有局限。DiffRefiner 通过混合规划范式与场景感知的扩散精炼机制,为这一挑战提供了切实可行的解决方案,也为 Nullmax 端到端系统的性能提升与落地部署提供了新思路。